分布式一致性协议 - Raft
条评论学习raft之前,给大家推荐一个网站,这个网站动画描述raft运行过程。在看文章时对照该网站,可以帮助更好的理解raft。
http://thesecretlivesofdata.com/raft/
相比于paxos,我们更应掌握raft。raft作为现在分布式系统首选的共识算法。zookeeper、cubby、oceanbase等系统都是在raft诞生之前开发的,所以都是使用了paxos或者对其进行改进。而后来的大多系统都选择了raft,比如consul、etcd等。
raft相比paxos的优点是:容易理解,容易实现。之所以说容易,是因为raft流程清晰、关键处给出了伪代码描述。相反,可真正用于工程实现的multi-paxos,lamport宗师只提出了个大概。
Raft术语科普以及总结
基于前两个篇对paxos和zab的介绍,我们对分布式协议有一定的基础,所以本文先给出总结。
三种成员身份
raft提供三种成员身份,领导者(leader)、跟随者(follower)、候选人(candidate)
- 跟随者:相当于paxos中的acceptor,接收和处理leader的消息,当leader故障时,主动推荐自己为候选人
- 候选人:向其他节点发送请求投票消息(Request Vote),如果获得大多数选票,则晋升为leader
- 领导者:处理写请求,管理日志复制、发送心跳消息。
两种运行阶段
raft强化了leader的地位,把整个协议可以清楚的分割成两个部分,并利用日志的连续性做了一些简化:
- leader在时,由leader向follower同步日志。
- leader挂掉了,选一个新leader,leader选举算法。
两类rpc消息
- 请求投票消息(request vote),用于选举leader。
- 追加条目消息(append entry),用于心跳消息或日志复制消息。该包含当前最大的日志项。
raft与multi-paxos的区别
- 不是所有节点都能当选leader
只有日志最完整的才能当选leader,而multi-paxos则不需要保证这一点,也意味multi-paxos需要额外的流程从其它节点获取已经被提交的日志。 - 日志是连续的
日志的连续性蕴含了这样一条性质:如果两个不同节点上相同序号的日志,那么这和这之前的日志必然也相同的 - 简化的二阶段
Leader选举
在节点刚启动状态下,都处于follower状态。同时每个节点会为自己设置一个等待leader心跳消息的随机超时时间。当在超时时间之内没有收到来自leader的心跳信息时,则会推荐自己为candidate。随后增加自己的任期编号,并以candidate的身份发起请求投票消息,推荐自己为leader,当获得大多数选票后,晋升leader,发送心跳消息。
选举过程
例如,存在A、B、C三个节点的raft集群刚启动时,都处于follower状态,其中A超时时间为100ms,B超时时间为200ms,C超时时间为300ms。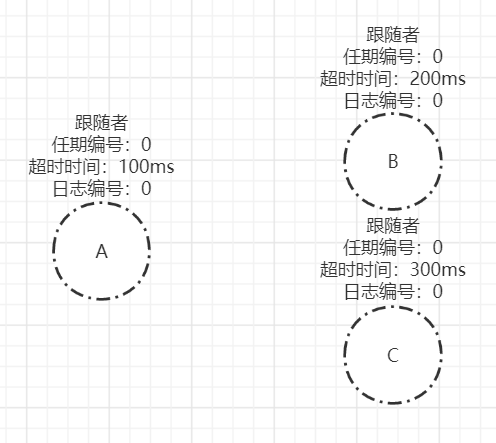
由于集群中不存在leader,A、B、C三个节点都不会收到来自leader心跳信息。其中,A节点的超时时间最小,则最先修改自己状态为candidate,并增加自己的任期编号为1,发起请求投票消息。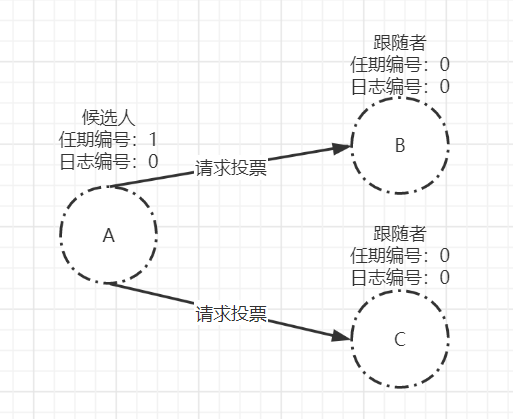
节点A的选票会投给自己,而节点B、C收到candidate的请求投票消息。根据投票规则:
- 任期编号大的节点拒绝投票给任期编号的小的请求投票消息
- 最后一条日志编号大的拒绝投票给最后一条日志编号小的节点
- 一个任期编号只投出一张选票
- 先来先获得投票
明显,B、C的任期编号小于A的任期,也不存在最大的日志编号,并且任期编号为1的选票还没有投给任何人,则将任期为1的选票投给节点A,并更新自己的任期编号。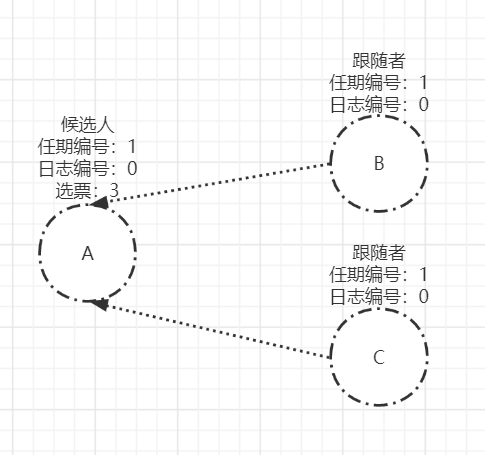
节点A获得包括自己在内的3个选票,赢得大多数选票。其中赢得过半选票也是存在随机超时时间的。如果在超时时间内,则晋升为leader,否则发起新的一轮选举。晋升leader后,则向其他节点发送心跳信息,维护自己的leader角色。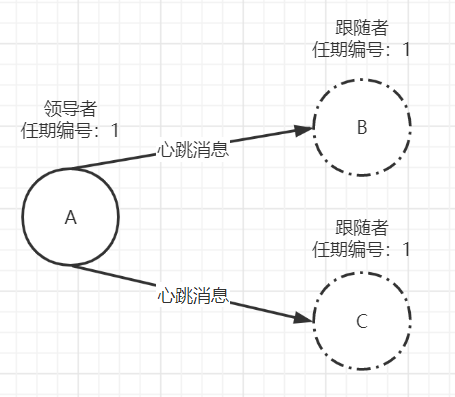
选举规则
整个选举过程相对来说,比较简单。具体细节还得挑几个点,单独来说:
- 随机超时时间
在basic-paxos中,通常会描述“活性”一词,是指两个提案同时提出,互相争取选票,导致另一个提案在第二阶段获取不到大多数选票。在muilt-paxos中,leader的选举,而会存在瓜分选票的情况。而raft巧妙的通过随机超时时间,避免了两个candidate同时竞选leader。需要注意,随机超时时间包含两个方面:- follower等待leader心跳信息超时的时间间隔。
- candidate在一个随机时间间隔内,没有赢得过半票数,那么选举无效了,需要发起新一轮的选举。
- 一届任期只投出一张选票,先来先获得投票
比如:B节点先后收到A、C任期编号为1的请求投票消息,B节点则将选票投给A节点。至于C节点的请求投票消息,B节点在任期编号为1的已经没有选票可投了。 - 任期编号大的节点拒绝投票给任期编号的小的请求投票消息
实际上,raft协议在leader选举阶段,由于老leader可能也还存活,也会存在不只一个leader的情形,只是不存在任期编号一样的两个leader。因为选举算法要求leader得到同一个任期编号的多数派的同意,同时赞同的成员会承诺不接受任期编号更小的任何消息。这样可以根据任期编号大小来区分谁是合法的leader。 - 最后一条日志编号(uncommited)大的拒绝投票给最后一条日志编号(uncommited)小的节点
这一条则是为了保证,只有日志完整度高的节点才能当选leader。这样则可以节省在当选leader后,与各节点比对日志的时间。
日志同步
在raft中,数据都是以日志的形式存在的,客户端每一次的写请求,都会封装成一个日志项(log entry)记录在日志中。所以处理客户端的写请求,就是把日志项(log entry)同步给其他节点并应用到各自状态机的过程。日志同步则可以认为就是处理写请求。
一条日志项(log entry)又包含:用户数据、索引值、任期编号。
- 用户数据,指客户端写请求中的数据,一般是对某个值的修改。
- 索引值,日志项的id,一个连续的单调递增的数字
- 任期编号,指创建该日志项的leader的任期编号
在上面总结中,有提到简化的二阶段协议,则是指日志同步阶段。其实在raft之前lamport宗师也有提到如何优化multi-paxos,其中就有优化为一阶段提交。而raft则在日志同步中做出了实践。
具体实现,在raft中,leader接收到写请求,进入第一阶段。leader将写请求封装为log entry追加到自己的日志中,并发送日志复制消息,将需要同步的log entry复制到集群中其他节点上。如果leader收到大多数节点都成功写入该log entry。那么就将该log entry提交到自己的状态机,同时返回成功给客户端。否则返回错误给客户端。
而follower则是在接收到leader的心跳信息或者新的日志复制消息后,如果follower发现leader已经提交了某条log entry,而自己还没提交,那么follower就将这条log entry提交到自己的状态机中。
算法模拟
存在3节点的集群,A为leader,B、C为follower。当客户端向leader发送set 5的请求,leader收到后,会将其封装成log entry追加到自己的日志中。然后通过日志复制消息时将更改发送给follower。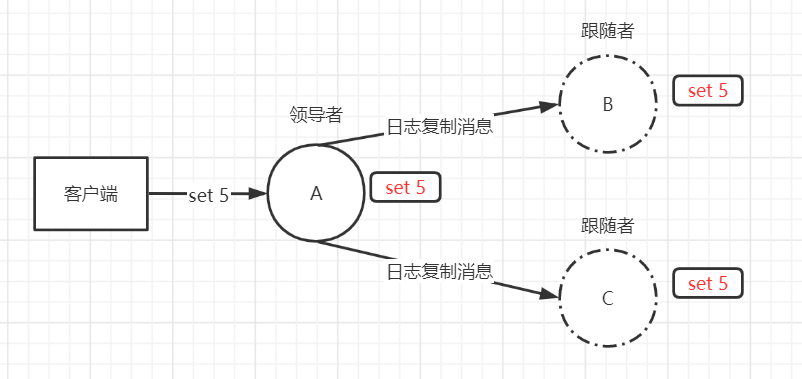
follower收到消息后,将该log entry追加到自己的日志中,并向leader返回成功响应。当leader收到大多数节点的成功响应后,则在自己的状态机中提交该log entry,并向客户端返回成功。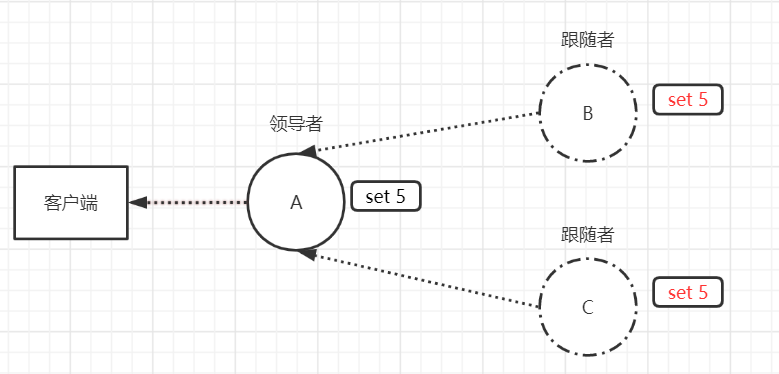
在下一次追加条目消息(心跳消息、日志复制消息)中,会携带leader最新修改的log entry。follower收到后,则会提交之前尚未提交的log entry。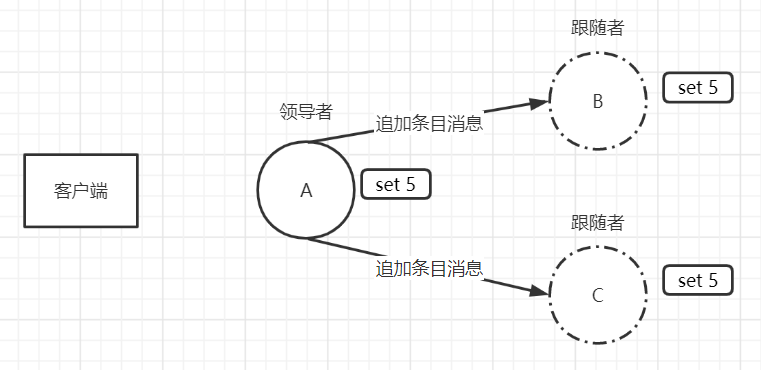
follower完成提交后,即达成本次共识。
网络分区、宕机恢复
当集群中出现网络分区,导致产生了两个小集群时,每个集群都存在自己的leader。或者上一任leader宕机恢复后加入集群时,存在两个leader的情况。raft为此也制定了一些特殊的规定:根据任期编号大小来区分谁是合法的leader。例如:当一个candidate或者leader发现自己的任期编号比其他节点小,那么它会立即恢复成follower状态。
存在一个5节点集群,正常运行时,B节点为leader,其余A、C、D、E为follower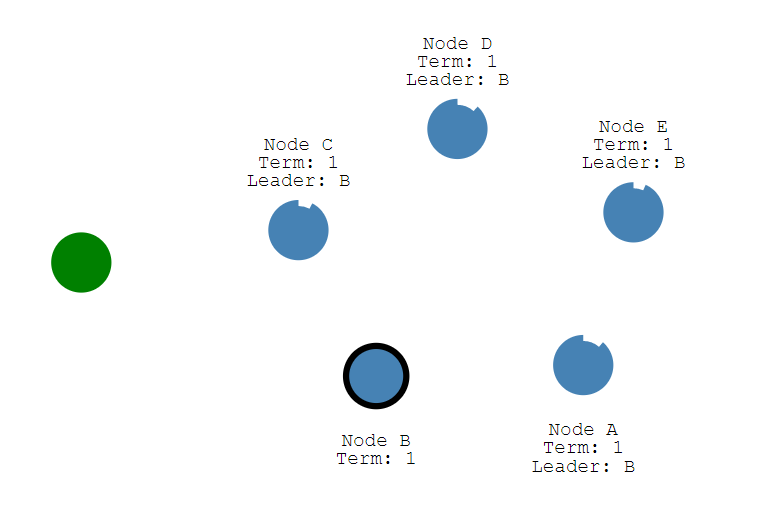
当出现网络分区,出现两个由B, A和C, D, E组成的小集群。并且B继续保持leader状态,C为新晋升的leader。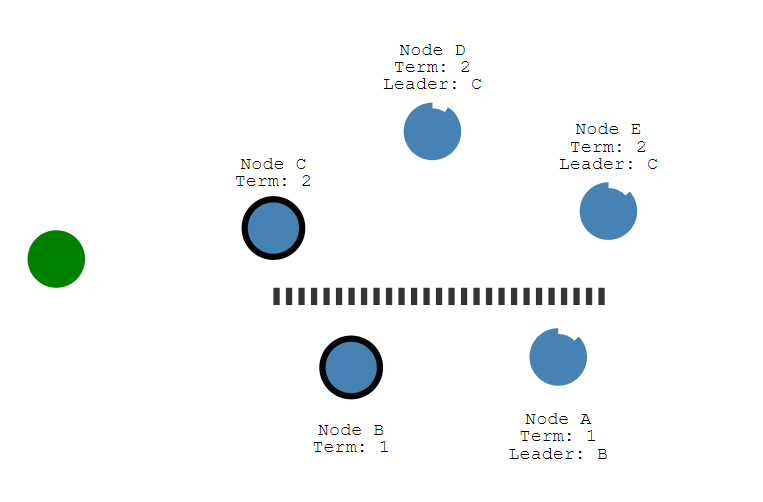
当此时,有写请求到B时,由于B不能获得多数票的支持,最终该写请求不会被提交,也不会返回给客户端成功的响应,将一直保持未提交的状态存在日志中。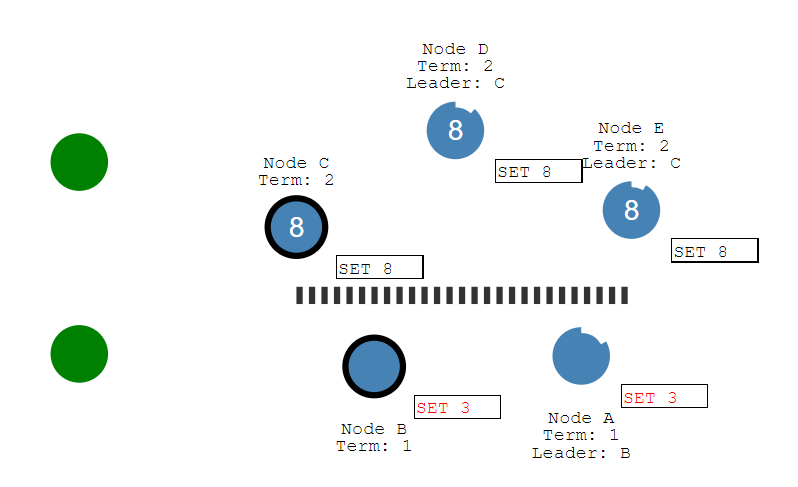
而当网络分区恢复后,B, A节点重新加入集群。当它们收到来自C节点的心跳消息时,发现C的任期编号比自己大,则会切换状态,抛弃掉自己有但C节点没有的log entry,并且同步C节点上的log entry。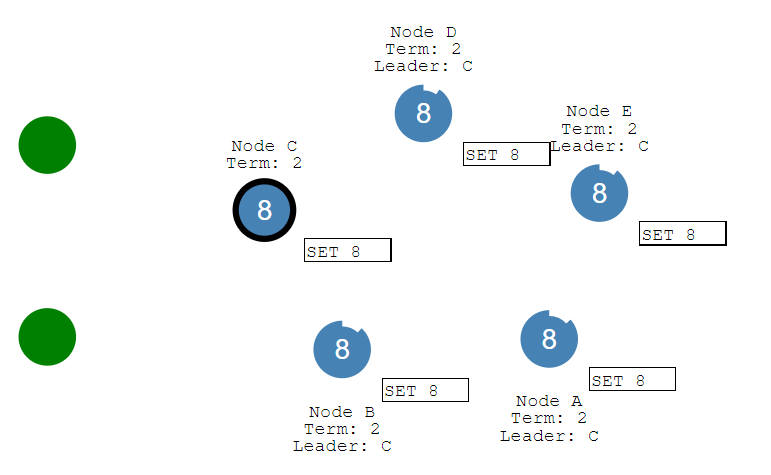
思考几个题目吧
1 | leader选举中,B节点的任期编号为1,日志编号为2。A节点任期编号为2,日志编号为1。 |
- 本文链接:https://www.ofcoder.com/2020/10/31/theory/%E5%88%86%E5%B8%83%E5%BC%8F%E4%B8%80%E8%87%B4%E6%80%A7%E5%8D%8F%E8%AE%AE%20-%20Raft/
- 版权声明:Copyright © 并发笔记 - ofcoder.com. Author by far.
分享